Use a data component in a flow
The URL data component loads content from a list of URLs. In the component’s URLs field, enter the URL you want to load To add multiple URL fields, click the add button Alternatively, connect a component that outputs theMessage type, like the Chat Input component, to supply your URLs from a component
API Request Component
This component makes HTTP requests using URLs or cURL commands.Setup Instructions
- Connect the Data output to a component that accepts the input (for example, connect the API Request component to a Chat Output component)
- In the API component’s URLs field, enter the endpoint for your request
- In the Method field, enter the type of request (GET, POST, PATCH, PUT, or DELETE)
- Optionally, enable the Use cURL button to create a field for pasting curl requests
- Click Playground, then click Run Flow to execute your request
Parameters
Parameters
Inputs
Outputs
| Name | Display Name | Info |
|---|---|---|
| urls | URLs | Enter one or more URLs, separated by commas. |
| curl | cURL | Paste a curl command to populate the dictionary fields for headers and body. |
| method | Method | The HTTP method to use. |
| use_curl | Use cURL | Enable cURL mode to populate fields from a cURL command. |
| query_params | Query Parameters | The query parameters to append to the URL. |
| body | Body | The body to send with the request as a dictionary (for POST, PATCH, PUT). |
| headers | Headers | The headers to send with the request as a dictionary. |
| timeout | Timeout | The timeout to use for the request. |
| follow_redirects | Follow Redirects | Whether to follow http redirects. |
| save_to_file | Save to File | Save the API response to a temporary file. |
| include_httpx_metadata | Include HTTPx Metadata | Include properties such as headers, status_code, response_headers, and redirection_history in the output. |
| Name | Display Name | Info |
|---|---|---|
| data | Data | The result of the API requests. Returns a Data object containing source URL and results. |
| dataframe | DataFrame | Converts the API response data into a tabular DataFrame format. |
File
This component loads and parses files of various supported formats and converts the content into a Data object. It supports multiple file types and provides options for parallel processing and error handling. To Load a Document- Click the Select files button
-
Select a local file or a file loaded with File management
Parameters
InputsOutputsName Display Name Info path Files The path to files to load. Supports individual files or bundled archives. file_path Server File Path A Data object with a file_pathproperty pointing to the server file or a Message object with a path to the file. Supersedes ‘Path’ but supports the same file types.separator Separator The separator to use between multiple outputs in Message format. silent_errors Silent Errors If true, errors do not raise an exception. delete_server_file_after_processing Delete Server File After Processing If true, the Server File Path is deleted after processing. ignore_unsupported_extensions Ignore Unsupported Extensions If true, files with unsupported extensions are not processed. ignore_unspecified_files Ignore Unspecified Files If true, Datawith nofile_pathproperty is ignored.use_multithreading [Deprecated] Use Multithreading Set ‘Processing Concurrency’ greater than 1to enable multithreading. This option is deprecated.concurrency_multithreading Processing Concurrency When multiple files are being processed, the number of files to process concurrently. Default is 1. Values greater than 1 enable parallel processing for 2 or more files. Name Display Name Info data Data The parsed content of the file as a Data object. dataframe DataFrame The file content as a DataFrame object. message Message The file content as a Message object.
Supported File Types
Text Files
.txt- Plain text files.md,.mdx- Markdown files.csv- Comma-separated values.json- JSON data files.yaml,.yml- YAML configuration files.xml- XML documents.html,.htm- HTML web pages.pdf- PDF documents.docx- Microsoft Word documents
Code Files
.py- Python source code.js- JavaScript files.ts,.tsx- TypeScript files.sh- Shell scripts.sql- SQL query files
Archive Formats
For bundling multiple files:.zip- ZIP archives.tar- TAR archives.tgz- Gzipped TAR archives.bz2- Bzip2 compressed files.gz- Gzip compressed files
SQL Query
This component executes SQL queries on a specified database.Parameters
Parameters
Inputs
Outputs
| Name | Display Name | Info |
|---|---|---|
| query | Query | The SQL query to execute. |
| database_url | Database URL | The URL of the database. |
| include_columns | Include Columns | Include columns in the result. |
| passthrough | Passthrough | If an error occurs, return the query instead of raising an exception. |
| add_error | Add Error | Add the error to the result. |
| Name | Display Name | Info |
|---|---|---|
| result | Result | The result of the SQL query execution. |
URL
This component fetches content from one or more URLs, processes the content, and returns it in various formats. It supports output in plain text or raw HTML. In the component’s URLs field, enter the URL you want to load- To use this component in a flow, connect the DataFrame output to a component that accepts the input. For example, connect the URL component to a Chat Output component.
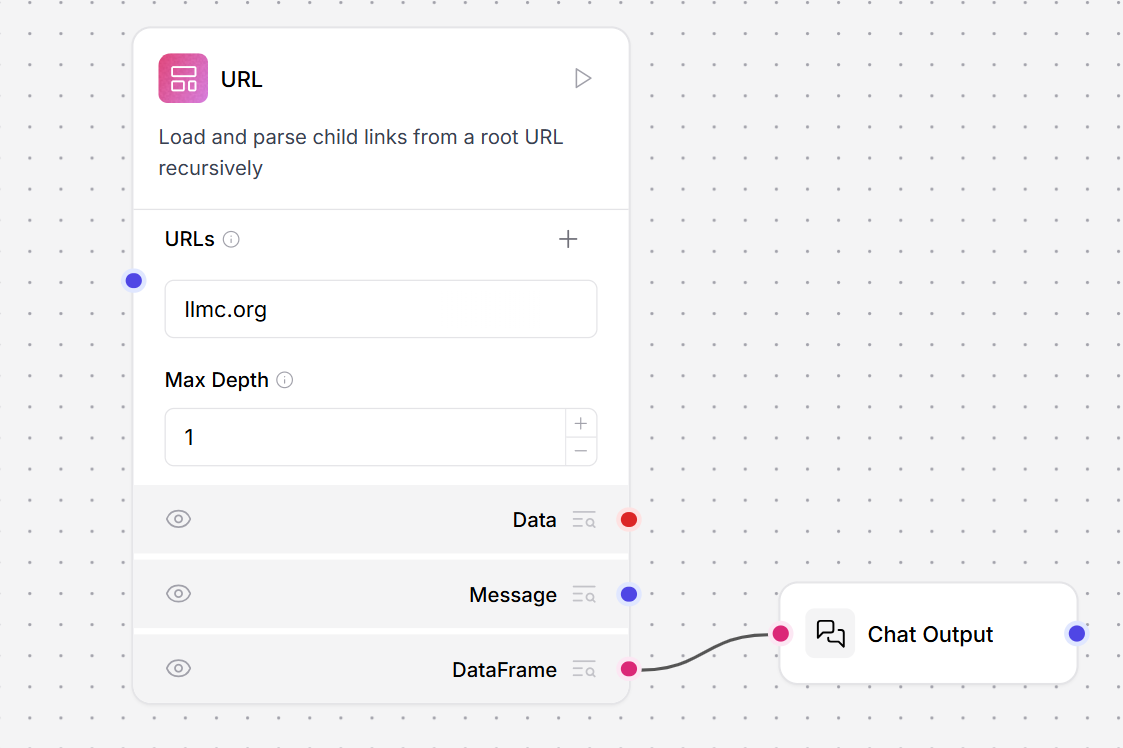
- In the URL component’s URLs field, enter the URL for your request. This example uses
llmc.org. - Optionally, in the Max Depth field, enter how many pages away from the initial URL you want to crawl. Select
1to crawl only the page specified in the URLs field. Select2to crawl all pages linked from that page. The component crawls by link traversal, not by URL path depth. - Click Playground, and then click Run Flow. The text contents of the URL are returned to the Playground as a structured DataFrame.
- In the URL component, change the output port to Message, and then run the flow again. The text contents of the URL are returned as unstructured raw text, which you can extract patterns from with the Regex Extractor tool.
- Connect the URL component to a Regex Extractor and Chat Output.
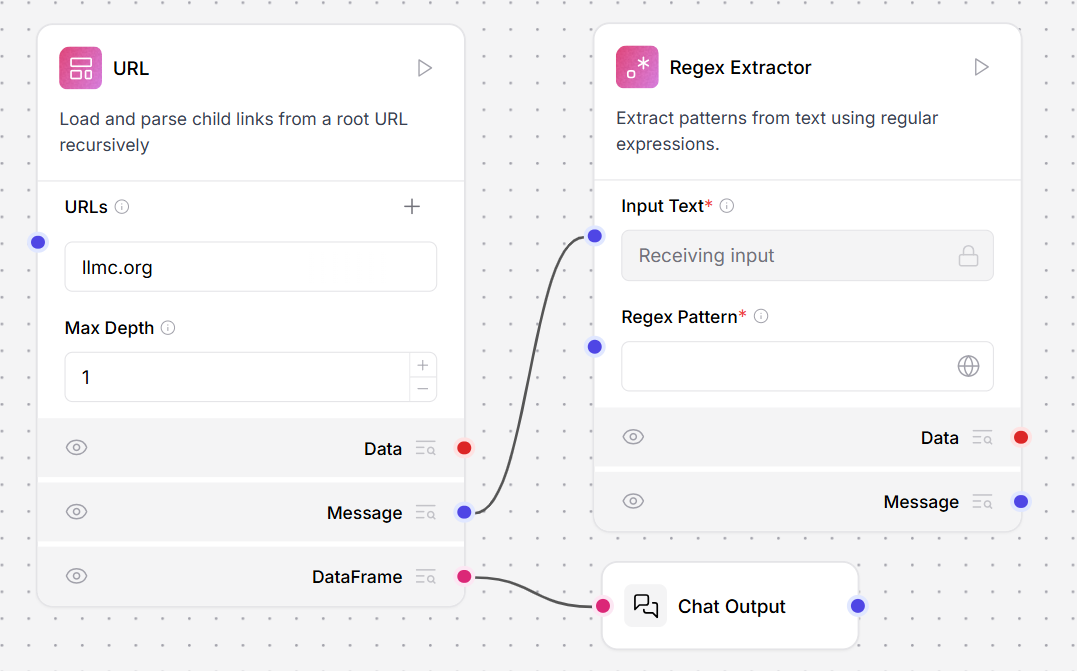
- In the Regex Extractor tool, enter a pattern to extract text from the URL component’s raw output. This example extracts the first paragraph from the “In the News” section of
https://en.wikipedia.org/wiki/Main_Page.
Parameters
Parameters
Inputs
Outputs
| Name | Display Name | Info |
|---|---|---|
| urls | URLs | Click the ’+’ button to enter one or more URLs to crawl recursively. |
| max_depth | Max Depth | Controls how many ‘clicks’ away from the initial page the crawler will go. |
| prevent_outside | Prevent Outside | If enabled, only crawls URLs within the same domain as the root URL. |
| use_async | Use Async | If enabled, uses asynchronous loading which can be significantly faster but might use more system resources. |
| format | Output Format | Output Format. Use Text to extract the text from the HTML or HTML for the raw HTML content. |
| timeout | Timeout | Timeout for the request in seconds. |
| headers | Headers | The headers to send with the request. |
| Name | Display Name | Info |
|---|---|---|
| data | Data | A list of Data objects containing fetched content and metadata. |
| text | Message | The fetched content as formatted text. |
| dataframe | DataFrame | The content formatted as a DataFrame object. |
Webhook
This component defines a webhook trigger that runs a flow when it receives an HTTP POST request. If the input is not valid JSON, the component wraps it in apayload object so that it can be processed and still trigger the flow. The component does not require an API key.
When you add a Webhook component to a flow, the flow’s API access pane exposes an additional Webhook cURL tab that contains a POST /v1/webhook/$FLOW_ID code snippet. You can use this request to send data to the Webhook component and trigger the flow. For example:
To test the webhook component:
- Add a Webhook component to the flow.
- Connect the Webhook component’s Data output to the Data input of a Parser component.
- Connect the Parser component’s Parsed Text output to the Text input of a Chat Output component.
- In the Parser component, under Mode, select Stringify. This mode passes the webhook’s data as a string for the Chat Output component to print.
- To send a POST request, copy the code from the Webhook cURL tab in the API pane and paste it into a terminal.
- Send the POST request.
- Open the Playground. Your JSON data is posted to the Chat Output component, which indicates that the webhook component is correctly triggering the flow.
Parameters
Parameters
Inputs
Outputs
ation about creating a service account JSON, see Service Account JSON.Inputs
Outputs
| Name | Display Name | Description |
|---|---|---|
| data | Payload | Receives a payload from external systems through HTTP POST requests. |
| curl | cURL | The cURL command template for making requests to this webhook. |
| endpoint | Endpoint | The endpoint URL where this webhook receives requests. |
| Name | Display Name | Description |
|---|---|---|
| output_data | Data | Outputs processed data from the webhook input, and returns an empty Data object if no input is provided. If the input is not valid JSON, the component wraps it in a payload object. |
| Input | Type | Description |
|---|---|---|
| token_string | SecretStrInput | A JSON string containing OAuth 2.0 access token information for service account access. |
| query_item | DropdownInput | The field to query. |
| valid_operator | DropdownInput | The operator to use in the query. |
| search_term | MessageTextInput | The value to search for in the specified query item. |
| query_string | MessageTextInput | The query string used for searching. |
| Output | Type | Description |
|---|---|---|
| doc_urls | List[str] | The URLs of the found documents. |
| doc_ids | List[str] | The IDs of the found documents. |
| doc_titles | List[str] | The titles of the found documents. |
| Data | Data | The document titles and URLs in a structured format. |
Directory
This component recursively loads files from a directory and converts the content into Data objects. It supports filtering by file type, depth control, and optional multithreading for parallel processing. To Load a Directory- Enter the directory path or use the default current directory
- Optionally select specific file types to filter
- Set the search depth and enable recursive mode if needed
Paramters
Paramters
Inputs
Outputs
| Name | Display Name | Info |
|---|---|---|
| path | Path | Path to the directory to load files from. Defaults to current directory (’.‘) |
| types | File Types | File types to load. Select one or more types or leave empty to load all supported types. |
| depth | Depth | Depth to search for files. |
| max_concurrency | Max Concurrency | Maximum concurrency for loading files. |
| load_hidden | Load Hidden | If true, hidden files will be loaded. |
| recursive | Recursive | If true, the search will be recursive. |
| silent_errors | Silent Errors | If true, errors will not raise an exception. |
| use_multithreading | Use Multithreading | If true, multithreading will be used. |
| Name | Display Name | Info |
|---|---|---|
| data | Data | The loaded files as a list of Data objects. |
| dataframe | DataFrame | The loaded file content as a DataFrame object. |
Load Spreadsheet
This component loads and parses spreadsheet files (.xlsx, .xls) and converts the content into a searchable data format for analysis. It supports sheet selection, row limits, caching, and optimized loading for large files. To Load a Spreadsheet- Click the Select files button and upload an .xlsx or .xls file
- Optionally specify a sheet name (defaults to the first sheet)
- Configure row limits and caching as needed
Parameters
Parameters
Inputs
Outputs
| Name | Display Name | Info |
|---|---|---|
| path | Files | The path to the spreadsheet file to load. Supports .xlsx and .xls files. |
| file_path | Server File Path | A Data object with a file_path property pointing to the server file or a Message object with a path to the file. Supercedes ‘Path’ but supports same file types. |
| separator | Separator | Specify the separator to use between multiple outputs in Message format. |
| silent_errors | Silent Errors | If true, errors will not raise an exception. |
| delete_server_file_after_processing | Delete Server File After Processing | If true, the Server File Path will be deleted after processing. |
| ignore_unsupported_extensions | Ignore Unsupported Extensions | If true, files with unsupported extensions will not be processed. |
| ignore_unspecified_files | Ignore Unspecified Files | If true, Data with no file_path property will be ignored. |
| sheet_name | Sheet Name | Name of the sheet to load (default: first sheet). |
| max_rows | Max Rows | Maximum number of rows to load (0 = all rows). |
| include_index | Include Row Index | Include row index as a column. |
| text_key | Text Key | The key to use for the text column. Defaults to ‘text’. |
| enable_caching | Enable Caching | Cache loaded data to avoid reloading for subsequent queries. |
| cache_dir | Cache Directory | Directory to store cached data (default: system temp directory). |
| optimize_for_large_files | Optimize for Large Files | Use optimized loading for files with 100,000+ rows. |
| chunk_size | Chunk Size | Number of rows to process in chunks for large files. |
| Name | Display Name | Info |
|---|---|---|
| data_list | Data List | The parsed spreadsheet content as a list of Data objects. |
| summary | Data Summary | Summary information about the loaded data including total rows, columns, and sample data. |
| dataframe | DataFrame | The spreadsheet content as a DataFrame object for SQL queries. |
Recursive URL Crawler
This component loads and parses child links from a root URL recursively. It crawls web pages up to a specified depth and extracts content in text or HTML format. To Crawl URLs- Enter one or more URLs by clicking the + button
- Set the Max Depth to control how many link levels to crawl
- Configure output format (Text or HTML)
Parameters
Parameters
Inputs
| Name | Display Name | Info |
|---|---|---|
| urls | URLs | Enter one or more URLs to crawl recursively, by clicking the ’+’ button. |
| max_depth | Max Depth | Controls how many ‘clicks’ away from the initial page the crawler will go: depth 1: only the initial page; depth 2: initial page + all pages linked directly from it; depth 3: initial page + direct links + links found on those pages. Note: This is about link traversal, not URL path depth. |
| prevent_outside | Prevent Outside | If enabled, only crawls URLs within the same domain as the root URL. This helps prevent the crawler from going to external websites. |
| use_async | Use Async | If enabled, uses asynchronous loading which can be significantly faster but might use more system resources. |
| format | Output Format | Output Format. Use ‘Text’ to extract the text from the HTML or ‘HTML’ for the raw HTML content. |
Outputs
| Name | Display Name | Info |
|---|---|---|
| data | Data | The crawled content as a list of Data objects. |
| text | Message | The crawled content as a concatenated Message object. |
| dataframe | DataFrame | The crawled content as a DataFrame object. |
S3 Bucket Uploader
This component uploads files to an Amazon S3 bucket. It supports two upload strategies: storing parsed data or uploading the original file as-is, with options for path prefixing and stripping. To Upload Files to S3- Provide your AWS Access Key ID and AWS Secret Key
- Enter the Bucket Name
- Connect Data inputs from upstream components
- Choose an upload strategy
Parameters
Parameters
Inputs
| Name | Display Name | Info |
|---|---|---|
| aws_access_key_id | AWS Access Key ID | AWS Access key ID. |
| aws_secret_access_key | AWS Secret Key | AWS Secret Key. |
| bucket_name | Bucket Name | Enter the name of the bucket. |
| strategy | Strategy for file upload | Choose the strategy to upload the file. By Data means that the source file is parsed and stored as LLM Controls data. By File Name means that the source file is uploaded as is. |
| data_inputs | Data Inputs | The data to split. |
| s3_prefix | S3 Prefix | Prefix for all files. |
| strip_path | Strip Path | Removes path from file path. |
Outputs
| Name | Display Name | Info |
|---|---|---|
| data | Writes to AWS Bucket | Processes and uploads files to the configured S3 bucket |