Use a model component in a flow
Model components receive inputs and prompts for generating text, and the generated text is sent to an output component. The model output can also be sent to the Language Model port and on to a Parse Data component, where the output can be parsed into structured Data objects. This example has the OpenAI model in a chatbot flow.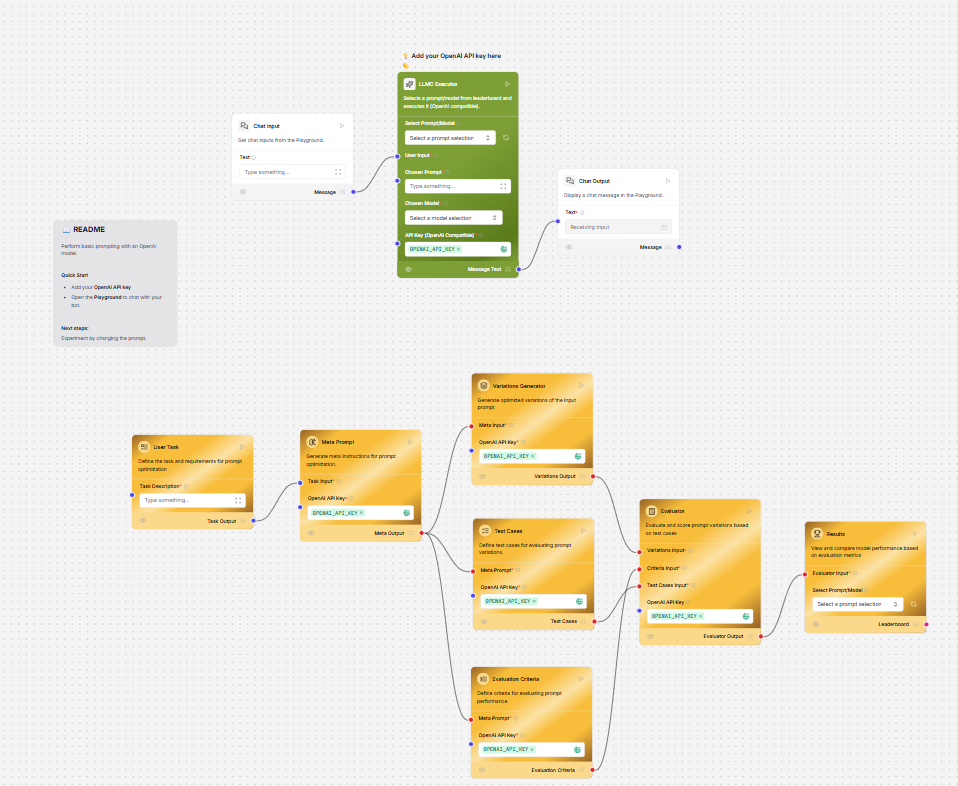
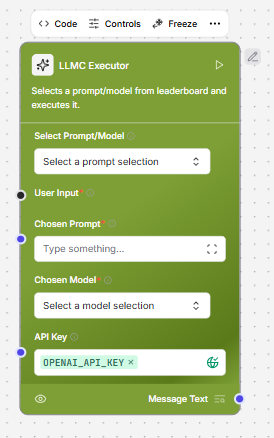
LLMC Executor
The LLMC Executor is a user-friendly interface designed to streamline interactions with AI language models, such as those from OpenAI. It plays a central role in allowing users to experiment with different prompts and models to generate high-quality AI responses. By integrating with API keys, the executor enables seamless communication with external AI services. Users can effortlessly select prompts , either manually or through integration with a Prompt Optimizer Flow and choose from available AI models using intuitive dropdown menus. Once configured, the tool provides a clean and efficient workflow where users input text, trigger the request with a single click, and receive intelligent outputs in real-time. This makes LLMC Executor an essential component for testing, optimizing, and comparing AI-generated responses across various configurations.Key usage highlights
- Prompt & Model Selection: Choose from a set of predefined prompts and models using dropdowns. Your selections are automatically displayed for clarity.
-
Secure API Access: Enter your API key to enable access to the chosen model. This is required for the tool to work.
AIML
This component creates a ChatOpenAI model instance using the AIML API. For more information, see AIML documentation.Parameters
Parameters
Inputs
Outputs
Amazon Bedrock
This component generates text using Amazon Bedrock LLMs. For more information, see Amazon Bedrock documentation.Parameters
Parameters
Inputs
Outputs
Anthropic
This component allows the generation of text using Anthropic Chat and Language models. For more information, see the Anthropic documentation.Parameters
Parameters
Inputs
Outputs
Azure OpenAI
This component generates text using Azure OpenAI LLM. For more information, see the Azure OpenAI documentation.Parameters
Parameters
Inputs
Outputs
Cohere
This component generates text using Cohere’s language models. For more information, see the Cohere documentation.Parameters
Parameters
Inputs
Outputs
DeepSeek
This component generates text using DeepSeek’s language models. For more information, see the DeepSeek documentation.Parameters
Parameters
Inputs
Outputs
Google Generative AI
This component generates text using Google’s Generative AI models. For more information, see the Google Generative AI documentation.Parameters
Parameters
Inputs
Outputs
Groq
This component generates text using Groq’s language models.-
To use this component in a flow, connect it as a Model in a flow like the Basic prompting flow, or select it as the Model Provider if you’re using an Agent component.

- In the Groq API Key field, paste your Groq API key. The Groq model component automatically retrieves a list of the latest models. To refresh your list of models, click Refresh.
- In the Model field, select the model you want to use for your LLM.
- Click Playground and ask your Groq LLM a question. The responses include a list of sources.
Parameters
Parameters
Inputs
Outputs
Hugging Face API
This component sends requests to the Hugging Face API to generate text using the model specified in the Model ID field. The Hugging Face API is a hosted inference API for models hosted on Hugging Face, and requires a Hugging Face API token to authenticate.Steps to use Hugging Face API in Basic prompting flow:
- Create a Basic prompting flow.
- Replace the OpenAI model component with a Hugging Face API model component.
- In the Hugging Face API component, add your Hugging Face API token to the API Token field.
- Select a model from the Model ID dropdown (e.g., meta-llama/Llama-3.3-70B-Instruct).
- Open the Playground and ask a question to the model, and see how it responds.
- Try different models, and see how they perform differently.
Parameters
Parameters
Inputs
Outputs
IBM watsonx.ai
This component generates text using IBM WatsonX.ai foundation models. To use IBM watsonx.ai model components, replace a model component with the IBM watsonx.ai component in a flow. An example flow looks like the following: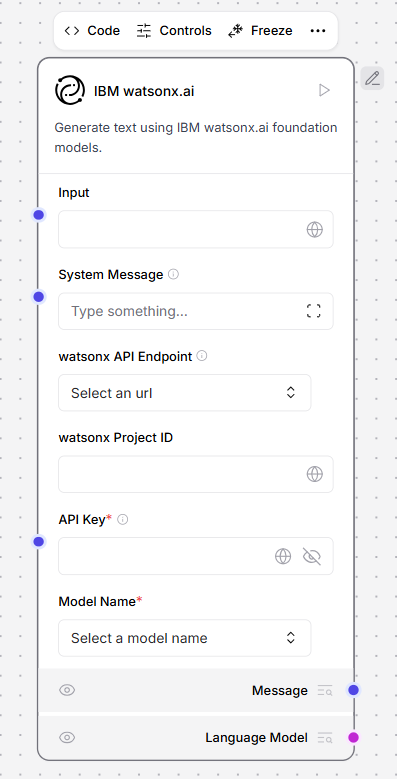
Parameters
Parameters
Inputs
Outputs
Language model
This component generates text using either OpenAI or Anthropic language models. Use this component as a drop-in replacement for LLM models to switch between different model providers and models. Instead of swapping out model components when you want to try a different provider, like switching between OpenAI and Anthropic components, change the provider dropdown in this single component. This makes it easier to experiment with and compare different models while keeping the rest of your flow intact. For more information, see the OpenAI documentation and Anthropic documentation.Parameters
Parameters
Inputs
Outputs
LMStudio
This component generates text using LM Studio’s local language models. For more information, see LM Studio documentation.Parameters
Parameters
Inputs
Outputs
Maritalk
This component generates text using Maritalk LLMs. For more information, see Maritalk documentation.Parameters
Parameters
Inputs
Outputs
Mistral
This component generates text using MistralAI LLMs. For more information, see Mistral AI documentation.Parameters
Parameters
Inputs
Outputs
Novita AI
This component generates text using Novita AI’s language models. For more information, see Novita AI documentation.Parameters
Parameters
Inputs
Outputs
NVIDIA
This component generates text using NVIDIA LLMs. For more information, see NVIDIA AI documentation.Parameters
Parameters
Inputs
Outputs
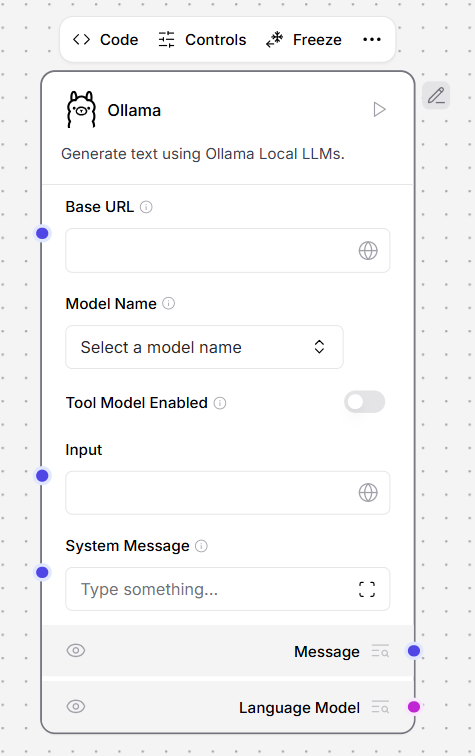
Ollama
This component generates text using Ollama’s language models. To use this component in a flow, connect LLM Controls to your locally running Ollama server and select a model.-
In the Ollama component, in the Base URL field, enter the address for your locally running Ollama server. This value is set as the
OLLAMA_HOSTenvironment variable in Ollama. The default base URL ishttp://localhost:11434. - To refresh the server’s list of models, click Refresh.
-
In the Model Name field, select a model. This example uses
llama3.2:latest. -
Connect the Ollama model component to a flow. For example, this flow connects a local Ollama server running a Llama 3.2 model as the custom model for an Agent component.
Parameters
Parameters
Inputs
Outputs
OpenAI
This component generates text using OpenAI’s language models. For more information, see OpenAI documentation.Parameters
Parameters
Inputs
Outputs
OpenRouter
This component generates text using OpenRouter’s unified API for multiple AI models from different providers. For more information, see OpenRouter documentation.Parameters
Parameters
Inputs
Outputs
Perplexity
This component generates text using Perplexity’s language models. For more information, see Perplexity documentation.Parameters
Parameters
Inputs
Outputs
Qianfan
This component generates text using Qianfan’s language models. For more information, see Qianfan documentation.Parameters
Parameters
Inputs
Outputs
SambaNova
This component generates text using SambaNova LLMs. For more information, see Sambanova Cloud documentation.Parameters
Parameters
Inputs
Outputs
VertexAI
This component generates text using Vertex AI LLMs. For more information, see Google Vertex AI documentation.Parameters
Parameters
Inputs
Outputs
xAI
This component generates text using xAI models like Grok. For more information, see the xAI documentation.Parameters
Parameters
Inputs
Outputs
DALL-E 3
This component generates images using OpenAI’s DALL-E 3 model. It accepts a text prompt and returns the generated image as a URL, base64-encoded data, or a Message with generation details.Parameters
Parameters