Use a helper component in a flow
Chat memory in LLM Controls is stored either in local LLM Controls tables withLCBufferMemory or connected to an external database.
The Store Message helper component stores chat memories as Data objects, and the Message History helper component retrieves chat messages as data objects or strings.
This example flow stores and retrieves chat history from an AstraDBChatMemory component with Store Message and Chat Memory components.
Batch Run
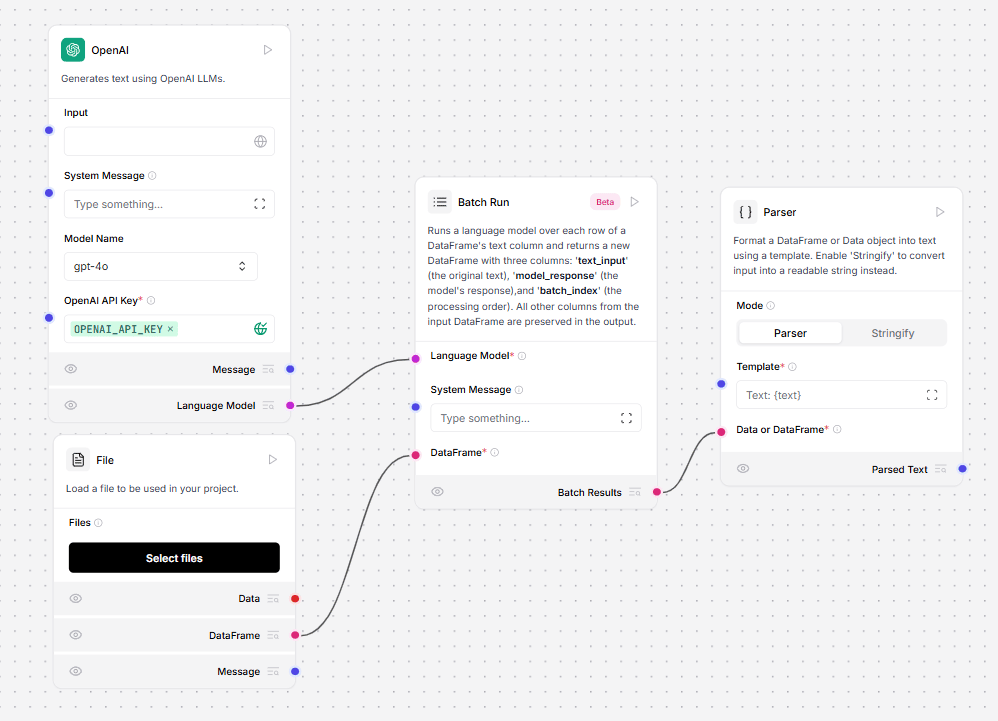
The Batch Run component runs a language model over each row of a DataFrame text column and returns a new DataFrame with the original text and an LLM response. The response contains the following columns:text_input: The original text from the input DataFrame.model_response: The model’s response for each input.batch_index: The processing order, with a0-based index.metadata(optional): Additional information about the processing.
- Connect a Model component to the Batch Run component’s Language model port.
- Connect a component that outputs a DataFrame, like the File component, to the Batch Run component’s DataFrame input.
- Connect the Batch Run component’s Batch Results output to a Parser component’s DataFrame input. The flow looks like this:
- In the Column Name field of the Batch Run component, enter a column name based on the data you’re loading from the File loader. For example, to process a column of
names, entername. - Optionally, in the System Message field of the Batch Run component, enter a System Message to instruct the connected LLM on how to process your file. For example,
create a business card for each name. - In the Template field of the Parser component, enter a template for using the Batch Run component’s new DataFrame columns. To use all three columns from the Batch Run component, include them like this:
- To run the flow, in the Parser component, click Run component.
- To view your created DataFrame, in the Parser component, click.
- Optionally, connect a Chat Output component, and open the Playground to see the output.
Parameters
Parameters
Inputs
Outputs
Current date
The Current Date component returns the current date and time in a selected timezone. This component provides a flexible way to obtain timezone-specific date and time information within an LLM Controls pipeline.Parameters
Parameters
Inputs
Outputs
ID Generator
This component generates a unique ID.Parameters
Parameters
Inputs
Outputs
Message history
infoBefore LLM Controls 1.1, this component was known as the Chat Memory component.
Parameters
Parameters
Inputs
Outputs
Message store
This component stores chat messages or text in LLM Controls tables or external memory. In this example, the Message Store component stores the complete chat history in a local LLM Controls table, which the Message History component retrieves as context for the LLM to answer each question.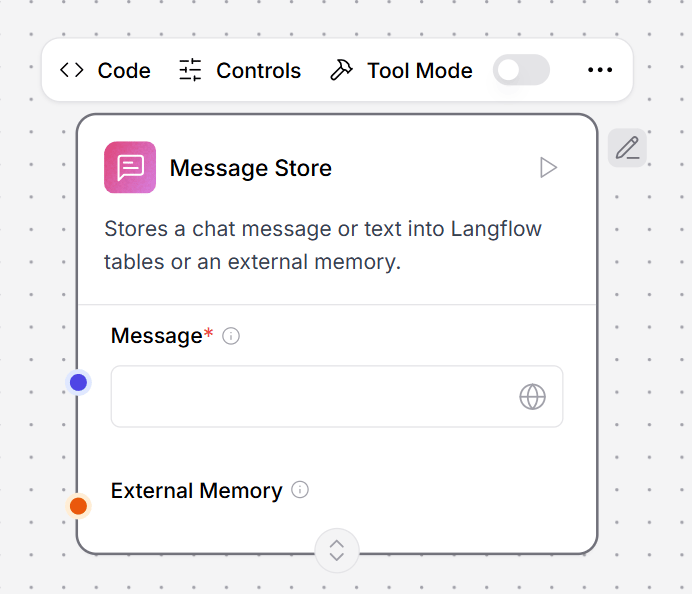
Parameters
Parameters
Inputs
Outputs
Structured output
This component transforms LLM responses into structured data formats. In this example from the Financial Report Parser template, the Structured Output component transforms unstructured financial reports into structured data.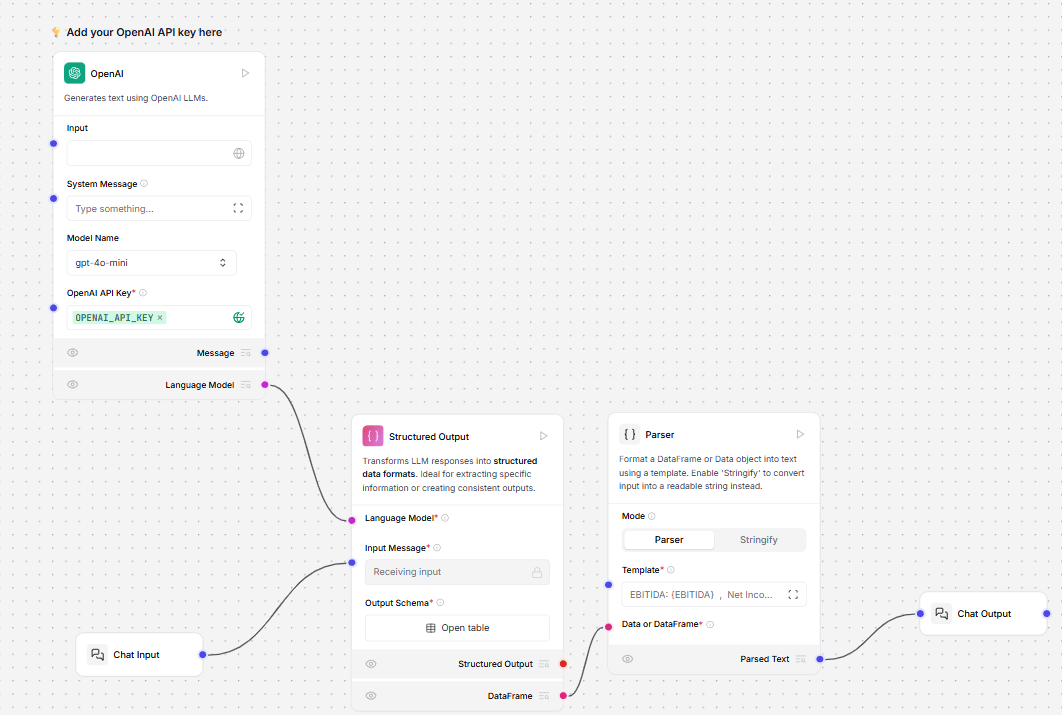
Format Instructions parameter to extract structured output from the unstructured text. Format Instructions is utilized as the system prompt for the Structured Output component.
In the Structured Output component, click the Open table button to view the Output Schema table. The Output Schema parameter defines the structure and data types for the model’s output using a table with the following fields:
- Name: The name of the output field.
- Description: The purpose of the output field.
- Type: The data type of the output field. The available types are
str,int,float,bool,list, ordict. The default istext. - Multiple: This feature is deprecated. Currently, it is set to
Trueby default if you expect multiple values for a single field. For example, alistoffeaturesis set toTrueto contain multiple values, such as["waterproof", "durable", "lightweight"]. Default:True.
output_schema table with curly braces.
For example, the template EBITDA: {EBITDA}, Net Income: {NET_INCOME}, GROSS_PROFIT: {GROSS_PROFIT} presents the extracted values in the Playground as EBITDA: 900 million, Net Income: 500 million, GROSS_PROFIT: 1.2 billion.
Parameters
Parameters
Inputs
Outputs